Modern organizations rely heavily on their cloud platforms, but resilience planning is often treated as a checkbox rather than an operational discipline. True readiness comes from understanding recovery objectives, validating backups through real restores, choosing the right multi-region architecture, and practicing well-documented runbooks.
This guide distills the core pieces of a working disaster recovery (DR) strategy—one that minimizes surprises when an incident actually occurs.
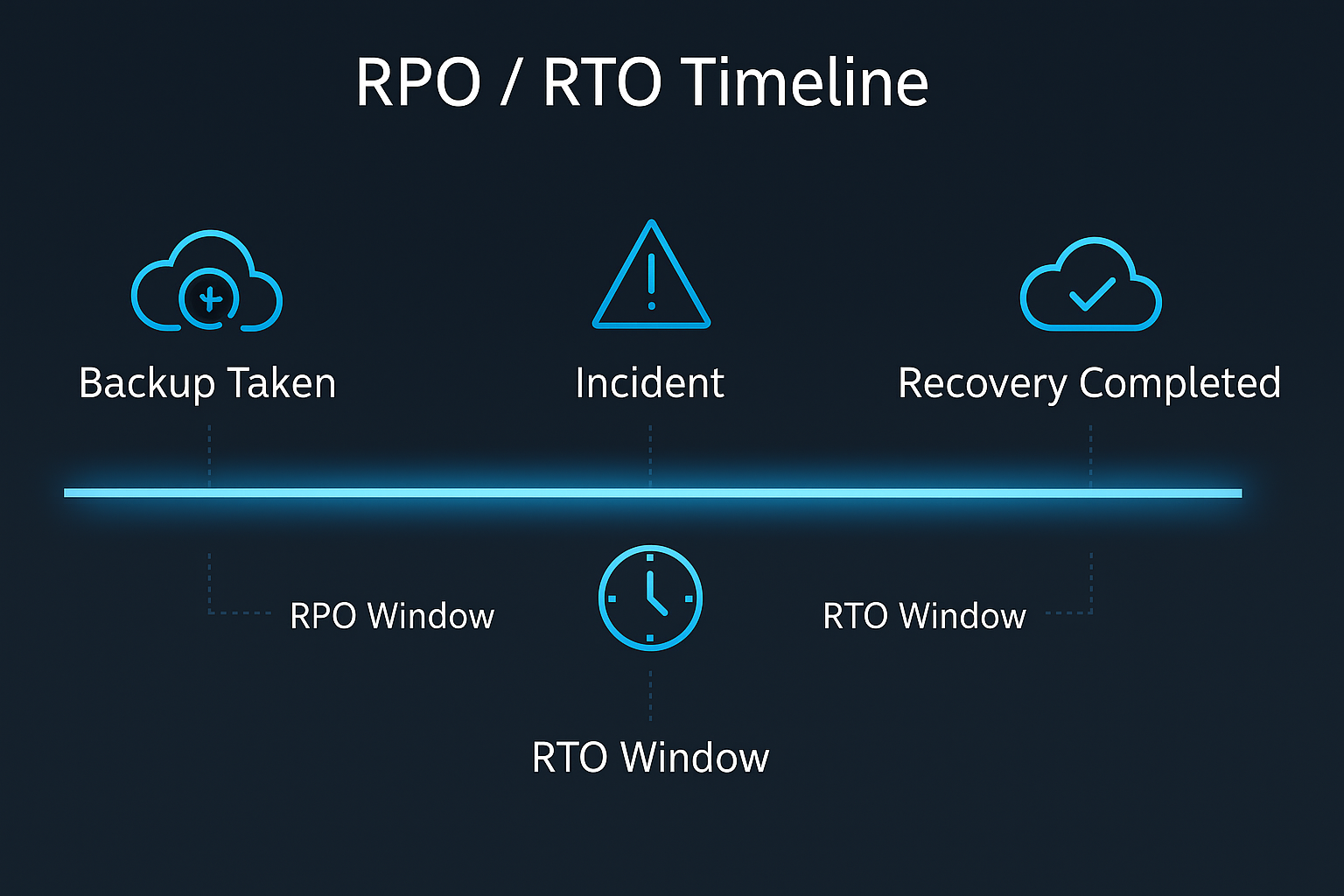
1. Understanding Recovery Objectives (RPO & RTO) in Practical Terms
Most teams know the definitions:
- RPO (Recovery Point Objective): How much data loss is acceptable?
- RTO (Recovery Time Objective): How long can the system be down?
But in practice, these numbers must map to real workloads—not aspirational targets.
What RPO looks like in the real world
- An RPO of 5 minutes means backups or replication must occur every 5 minutes.
- Databases must have:
- Point-in-time restore enabled
- Continuous transaction log backups
- Cross-region replication
What RTO means operationally
An RTO of 2 hours means you can:
- Rebuild infrastructure
- Restore data
- Rehydrate secrets and parameters
- Cut DNS over
- Validate health checks
- Restore application traffic
…all within 120 minutes.
That is only possible with automated provisioning (Terraform, Terragrunt, GitOps) and pre-validated runbooks.
RPO/RTO relationship (diagram)
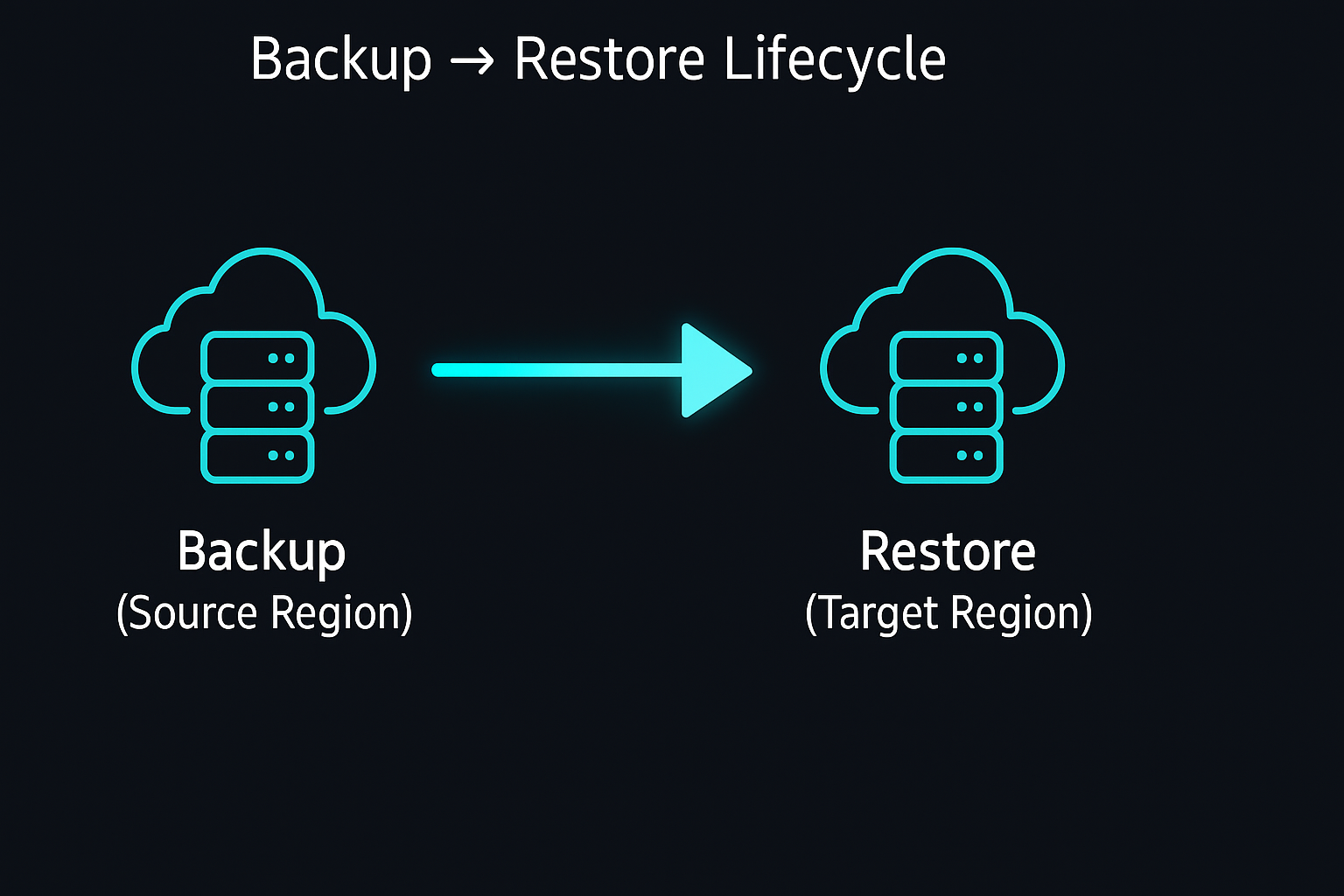
2. Backups vs. Restore Testing (They Are NOT the Same)
Saying “we take backups” is not the same as being able to restore them.
Backups are evidence of protection.
Restores are evidence of recovery.
Key considerations
- Backups must be automated and monitored.
- Backups should be copied cross-region.
- Restore tests must be executed on:
- A clean cluster
- A clean database
- A new VPC or subnet
- Application functionality must be validated after restore.
A real restore test should include:
- Rebuilding infrastructure via IaC
- Rehydrating workloads through GitOps
- Restoring:
- Kasten snapshots
- RDS point-in-time backups
- Blob/NFS backup files
- Validating:
- Secrets (ESO, Key Vault, SSM)
- Networking & DNS
- Application health
Backup vs restore lifecycle (diagram)
3. Active/Passive vs. Active/Active Multi-Region Patterns
Choosing the right topology impacts cost, performance, and operational complexity.
Active/Passive (most common, cost-efficient)
- One region handles all production traffic.
- Secondary region stays minimally provisioned.
- Failover via:
- DNS
- Global load balancers
- Kubernetes multi-region clusters
Choose Active/Passive when:
✔ Cost must stay predictable
✔ Traffic is not globally distributed
✔ Minute-level recovery is acceptable
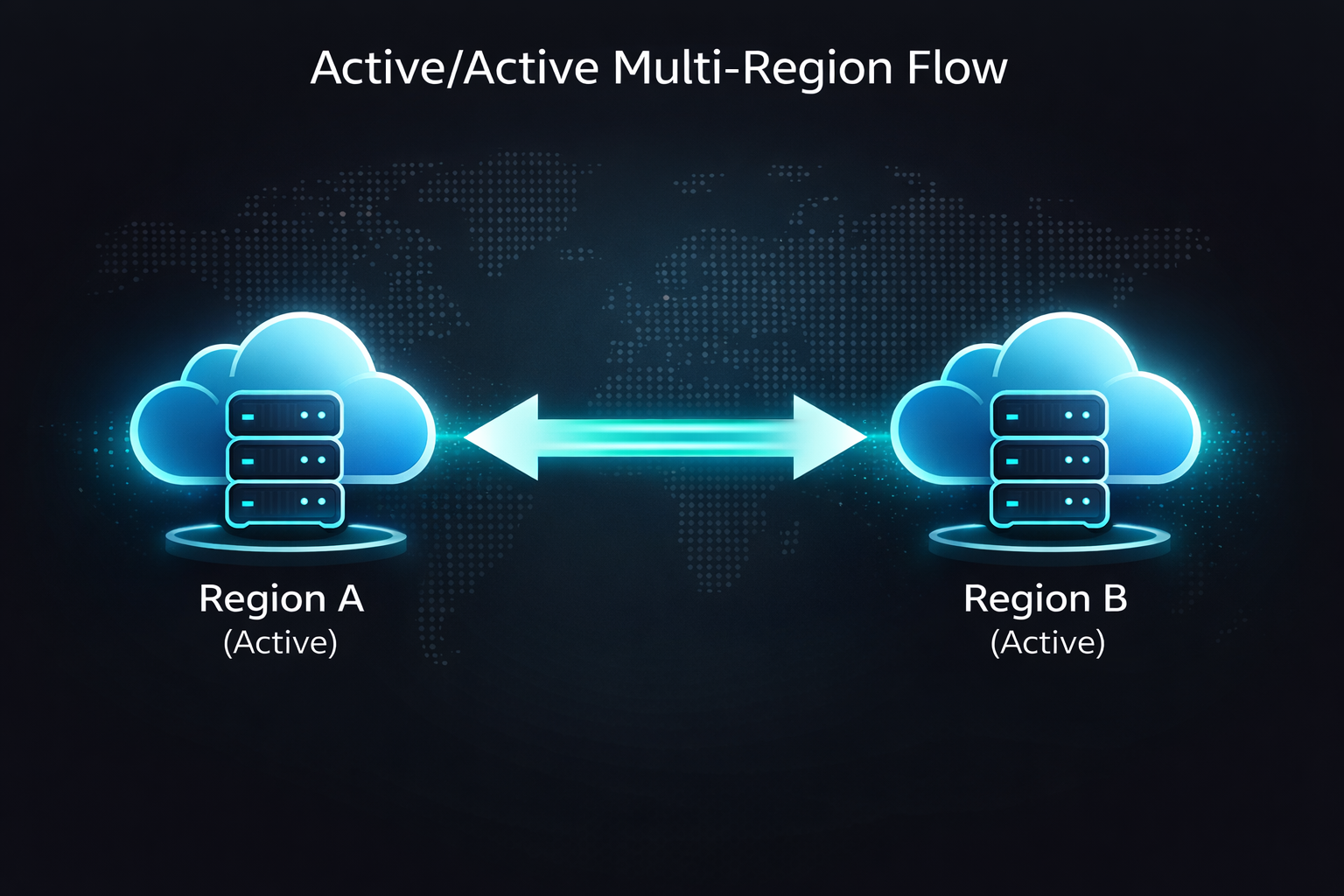
Active/Active (high cost, high performance)
- All regions actively serve traffic.
- Requires multi-master or conflict-free databases.
- Requires global load balancing + traffic steering.
Choose Active/Active when:
✔ Global low-latency is required
✔ Sub-second RTO
✔ Capacity for architectural complexity
Active/Passive vs Active/Active (diagram)
4. Documentation, Runbooks, and Disaster Recovery Drills
Documentation is the difference between hoping your DR works and knowing it will.
A complete DR runbook should include:
- Who declares a DR event
- Authority to trigger failover
- Detailed step-by-step workflows
- Infrastructure provisioning commands
- Validation checkpoints
- Rollback and recovery procedures
Runbooks must be:
- Version-controlled in GitHub
- Tested quarterly or semi-annually
- Updated after every infrastructure or application change
- Clear enough for new team members to execute
Drill types
| Drill Type | Purpose |
|---|---|
| Tabletop Exercise | Validate process without touching infrastructure |
| Partial Failover | Validate subsystems (DNS, backups, clusters) |
| Full DR Simulation | Deploy to secondary region and shift traffic |
| Region Blackhole Test | Simulate catastrophic regional outage |
DR runbook workflow (diagram)

5. Checklist: Practical Multi-Region DR Readiness Scorecard
Backups & Recovery
- ☐ Automated backups configured
- ☐ Cross-region replication enabled
- ☐ Restore test completed in last 90 days
- ☐ App-level validation performed
Multi-Region Architecture
- ☐ Clear Active/Passive or Active/Active decision
- ☐ Terraform/Terragrunt builds both regions identically
- ☐ GitOps (ArgoCD) deploys apps consistently
Operational Runbooks
- ☐ Documented failover procedures
- ☐ DNS & traffic routing steps defined
- ☐ On-call team trained
- ☐ DR drill completed this year
Observability & Alerts
- ☐ Synthetic checks in each region
- ☐ Region-level alerting
- ☐ Failover readiness dashboards
Conclusion
Multi-region resilience is not something you “set and forget.” It’s an ongoing discipline involving:
- Clear recovery expectations
- Validated restore procedures
- Thoughtful architecture trade-offs
- Documented runbooks
- Frequent drills
The organizations that perform best during outages aren’t lucky—they’re prepared.